BeautifulSoup을 사용하여 네이버 금융( finance.naver.com/sise/ ) 인기종목 top10, 상한가종목 top10을 가져와보겠다.
section2 환경에서 atom 실행시켜보자.
먼저, 인기종목 top10의 구조를 보자.

인기검색 종목의 html을 보면 간단하다.
id값이 popularItemList 의 자식들이 li로 감싸져있는것을 확인할 수 있다.
BeautifulSoup의 select 함수를 사용하여 리스트 값으로 가져 올 수 있는것이 느껴진다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from bs4 import BeautifulSoup
import urllib.request as req
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.detach(), encoding='utf-8')
url = 'https://finance.naver.com/sise/' #네이버 금융 url 주소
res = req.urlopen(url).read().decode('cp949') #utf-8 : 한글 깨짐, unicode_escape : 한글 깨짐, cp949로 변환해야한다.
soup = BeautifulSoup(res, "html.parser")
top10 = soup.select('#popularItemList > li > a') #선택자 id인 popularItemList에 존재하는 li값들의 a 태그들만 리스트 형태로 담는다.
print(top10) #리스트 형태로 담긴 정보들
for i, e in enumerate(top10, 1) :
print("순위 : {}, 이름 : {}".format(i, e.string))
|
cs |
download2-7-1.py
#popularItemList > li > a 를 통해 a태그의 값을 top10에 담아서 출력해보면, 리스트 형태로 볼 수 있다.
top10을 for문을 통해 a태그의 string값만 출력해보면 아래와 같이 검색 순위 리스트를 확인할 수 있다.

다음으로는 상한가 top10 종목을 확인해 보겠다.
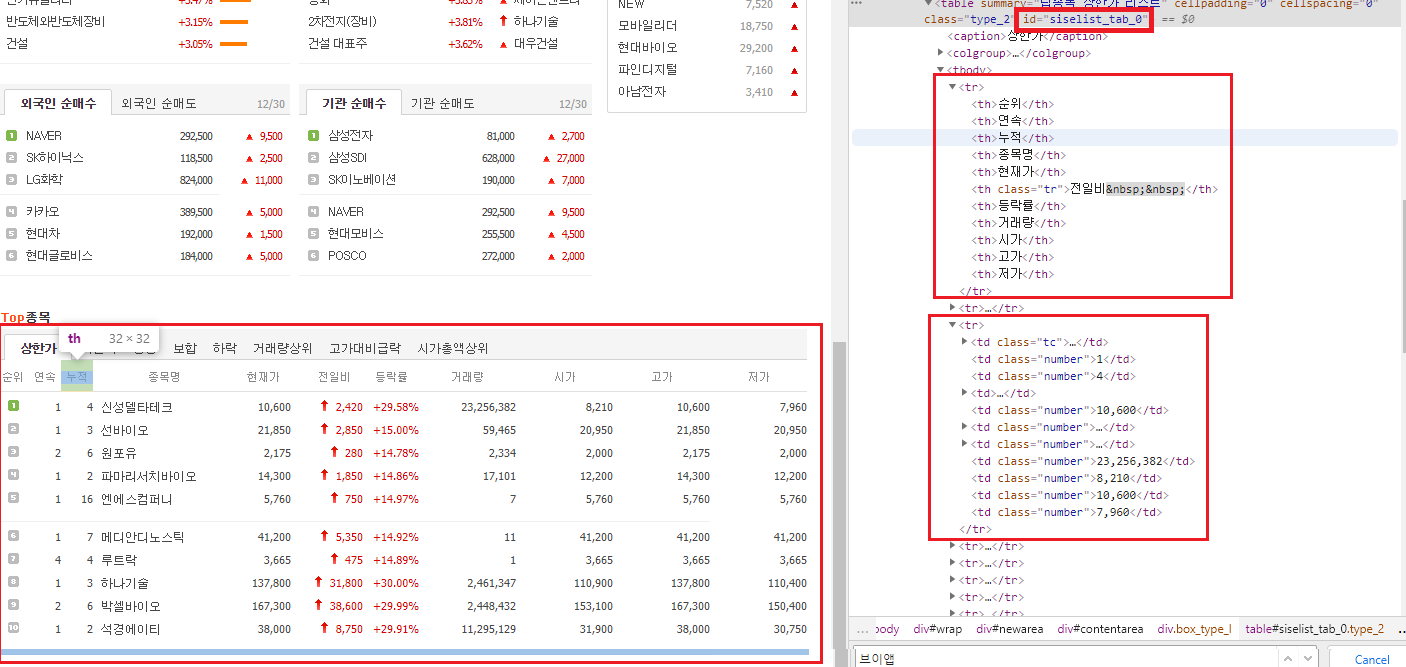
html 코드를 보게되면 siselist_tab_0인 아이디 내 tr값들이 정렬되어 있는데,
tr 태그의 개수가 top10 개수보다 더 많이있다.
top10 영역 이외의 tr들도 함께 묶여있기 때문인데, 이는 분기처리를 통해 top10 값만 가져올 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from bs4 import BeautifulSoup
import urllib.request as req
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.detach(), encoding='utf-8')
url = "http://finance.naver.com/sise/" #네이버 금융 url 주소
res = req.urlopen(url).read().decode('cp949') #utf-8 : 한글 깨짐, unicode_escape : 한글 깨짐, cp949로 변환해야한다.
soup = BeautifulSoup(res, "html.parser")
top10 = soup.select("#siselist_tab_0 > tr")
i = 1
for e in top10 :
if e.find("a") is not None : #tr 중 a태그가 존재하지 않는 html은 제외
print(i,e.select_one(".tltle").string)
i += 1
|
cs |
download2-7-2.py
siselist_tab_0 > tr 를 통해 tr값들을 담은 후, tr값에 a태그가 존재하지 않는 경우는 모두 제외시키고 출력했다.

'언어 > python&웹 크롤링' 카테고리의 다른 글
| [python&웹 크롤링] 13. requests 모듈 기초(2) (1) | 2021.01.03 |
|---|---|
| [python&웹 크롤링] 12. requests 모듈 기초(1) (0) | 2021.01.02 |
| [python&웹 크롤링] 10. BeautifulSoup 사용 및 웹 파싱 기초(2) (0) | 2020.12.28 |
| [python&웹 크롤링] 9. BeautifulSoup 사용 및 웹 파싱 기초(1) (0) | 2020.12.18 |
| [python&웹 크롤링] 8. youtube 동영상 다운로드 및 mp3 변환 (2) | 2020.12.09 |
